Making Data Useful
What on earth is data science?
The quest for a useful definition

Behold my pithiest attempt: “Data science is the discipline of making data useful.” Feel free to flee now or stick around of a tour of its three subfields.
The term no one really defined
If you poke around in the early history of the term data science, you see two themes coming together. Allow me to paraphrase for your amusement:
- Big(ger) data means more tinkering with computers.
- Statisticians can’t code their way out of a paper bag.
And thus, data science is born. The way I first heard the job defined is “A data scientist is a statistician who can code.” I’ll be full of opinions on that in a moment, but first, why don’t we examine data science itself?

I love how the 2003 launch of Journal of Data Science goes right for the narrowest possible scope: “By ‘Data Science’ we mean almost everything that has something to do with data.” So… everything, then? It’s hard to think of something that has nothing to do with information. (I should stop thinking about this before my head explodes.)
Since then, we’ve seen a multitude of opinions, from Conway’s well-traveled Venn diagram (below) to Mason and Wiggins’ classic post.
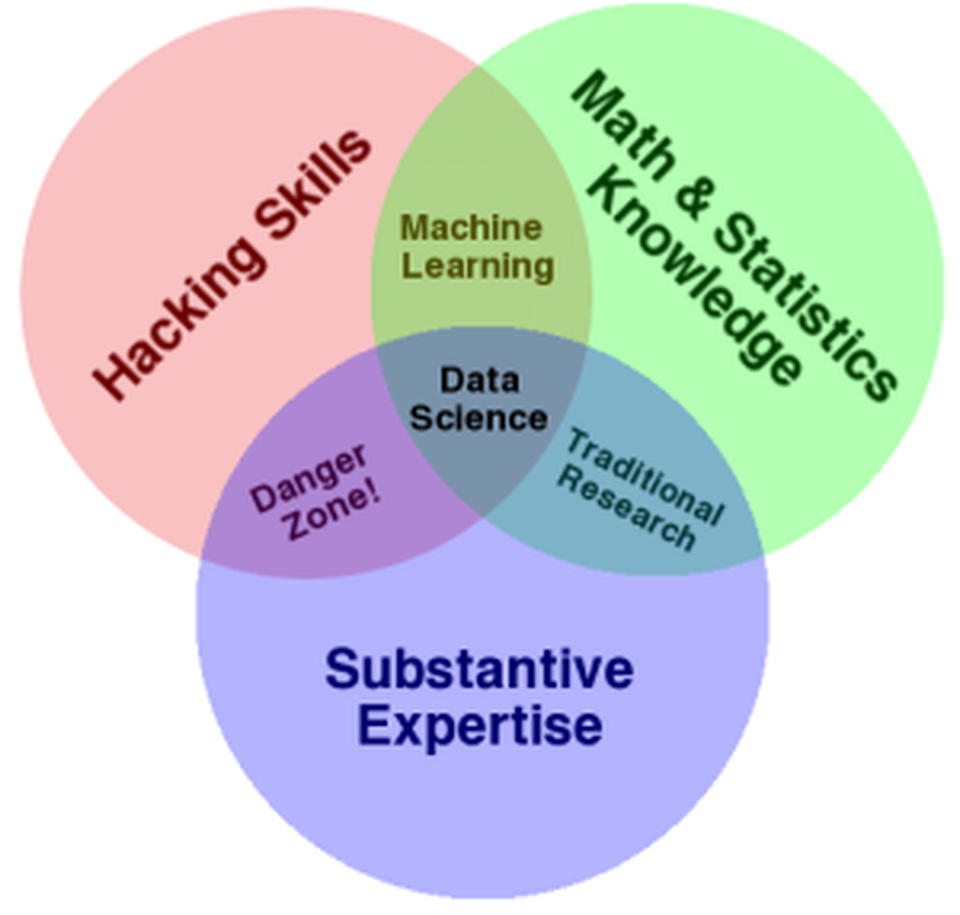
Wikipedia has one that’s very close to what I teach my students:
Data science is a ‘concept to unify statistics, data analysis, machine learning and their related methods’ in order to ‘understand and analyze actual phenomena’ with data.
That’s a mouthful, so let me see if I can make it short and sweet:
“Data science is the discipline of making data useful.”
What you’re thinking around about now might be, “Nice try, Cassie. It’s cute, but it’s an egregiously lossy reduction. How does the word ‘useful’ capture all of that jargon stuff?”
Well, okay, let’s argue it out with pictures.

What are these things and how do you know where you are on the map?
If you’re about try breaking them down by standard toolkits, slow down. The difference between a statistician and a machine learning engineer is not that one uses R and the other uses Python. The SQL vs R vs Python taxonomy is ill-advised for so many reasons, not least of which is that software evolves. (As of recently, you can even do ML in SQL.) Wouldn’t you prefer a breakdown that’ll last? In fact, just go ahead and unread this entire paragraph.
Perhaps worse is the favorite way novices split the space. Yup, you guessed it: by the algorithm (surprise! it’s how university courses are structured). Pretty please, don’t taxonomize by histograms vs t-tests vs neural networks. Frankly, if you’re clever and you have a point to make, you can use the same algorithm for any part of data science. It might look like Frankenstein’s monster, but I assure you it can be forced to do your bidding.
Enough with the dramatic buildup! Here’s the taxonomy I propose:

None-One-Many
What on earth is this? Why, decisions, of course! (Under incomplete information. When all the facts you need are visible to you, you can use descriptive analytics for making as many decisions as you please. Just look at the facts and you’re done.)
It’s through our actions — our decisions — that we affect the world around us.
I’d promised you we were going to talk about making data useful. To me, the idea of usefulness is tightly coupled with influencing real-world actions. If I believe in Santa Claus, it doesn’t particularly matter unless it might influence my behavior in some way. Then, depending on the potential consequences of that behavior, it might start to matter an awful lot. It’s through our actions — our decisions — that we affect the world around us (and invite it to affect us right back).
So here’s the new decision-oriented picture for you, complete with the three main ways to make your data useful.

Data-mining / Analytics
If you don’t know what decisions you want to make yet, the best you can do is go out there in search of inspiration. That’s called data-mining or analytics or descriptive analytics or exploratory data analysis (EDA) or knowledge discovery (KD), depending on which crowd you hung out with during your impressionable years.
Golden rule of analytics: only make conclusions about what you can see.
Unless you know how you intend to frame your decision-making, start here. The great news is that this one is easy. Think of your dataset as a bunch of negatives you found in a darkroom. Data-mining is about working the equipment to expose all the images as quickly as possible so you can see whether there’s anything inspiring on them. As with photos, remember not to take what you see too seriously. You didn’t take the photos, so you don’t know much about what’s off-screen. The golden rule of data-mining is: stick to what is here. Only make conclusions about what you can see, never about what you can’t see (for that you need statistics and lot more expertise).
Other than that, you can do no wrong. Speed wins, so start practicing.
Expertise in data-mining is judged by the speed with which you can examine your data. It helps not to snooze past the interesting nuggets.
The darkroom’s intimidating at first, but there’s not that much to it. Just learn to work the equipment. Here’s a tutorial in R and here’s one in Python to get you started. You can call yourself a data analyst as soon as you start having fun and you can call yourself an expert analyst when you’re able to expose photos (and all the other kinds of datasets) with lightning speed.

Statistical inference
Inspiration is cheap, but rigor is expensive. If you want to leap beyond the data, you’re going to need specialist training. As someone with undergrad and graduate majors in statistics, I may be just a tad biased here, but in my opinion statistical inference (statistics for short) is the most difficult and philosophy-laden of the three areas. Getting good at it takes the most time.
Inspiration is cheap, but rigor is expensive.
If you intend to make high-quality, risk-controlled, important decisions that rely on conclusions about the world beyond the data available to you, you’re going to have to bring statistical skills onto your team. A great example is that moment when your finger is hovering over the launch button for an AI system and it occurs to you that you need to check it works before releasing it (always a good idea, seriously). Step away from the button and call in the statistician.
Statistics is the science of changing your mind (under uncertainty).
If you want to learn more, I’ve written this 8-minute super-summary of statistics for your enjoyment.
Machine learning
Machine learning is essentially making thing-labeling recipes using examples instead of instructions. I’ve written a few posts about it, including whether it’s different from AI, how to get started with it, why businesses fail at it, and the first couple of articles in a series of plain-language takes on the jargon nitty gritties (start here). Oh, and if you want to share them with non-English-speaking friends, a bunch of them are translated here.
Data Science versus “Data Scientist”
Many different kinds of workers can be engaged in making data useful (check out my survey of top 10 roles for data science projects here). While all these roles participate in data science, I don’t think of all of them as data scientists.
This is a tricky can of worms. In my view, a data scientist is someone with expertise in all three areas (analytics, statistics, and ML/AI). Since I’m aware that my opinion on the data scientist job title is not the only one out there, I’ve tried to do justice to other viewpoints and what they mean for the data science labor market in a separate article.

Data engineering
What about data engineering, the work that delivers data to the data science team in the first place? Since it’s a sophisticated field in its own right, I prefer to shield it from data science’s hegemonic aspirations. Besides, it’s much closer in species to software engineering than to statistics.
The difference between data engineering and data science is a difference of before and after.
Feel free to see the data engineering versus data science difference as before versus after. Most of the technical work leading up to the birthing of the data (before) may comfortably be called “data engineering” and everything we do once some data have arrived (after) is “data science”.
Decision intelligence
Decision intelligence (DI) is all about decisions — including decision-making at scale with data — which makes it an engineering discipline. It augments the applied aspects of data science with ideas from the social and managerial sciences.
Decision intelligence adds components from the social and managerial sciences.
In other words, it’s a superset of those bits of data science not concerned with researchy things like creating fundamental methodologies for general-purpose use.
Still hungry? Here’s a breakdown of the roles in a data science project to entertain you while I go clack on my keyboard.
Thanks for reading! How about a course?
If you had fun here and you’re looking for an unboring leadership-oriented course designed to delight AI beginners and experts alike, here’s a little something I made for you:

P.S. Have you ever tried hitting the clap button here on Medium more than once to see what happens? ❤️
Liked the author? Connect with Cassie Kozyrkov
Let’s be friends! You can find me on Twitter, YouTube, Substack, and LinkedIn. Interested in having me speak at your event? Use this form to get in touch.
